
Hi!
I'd like to inform you about my experience with LDAP monitoring using the cn=monitor DN to query openLDAP. I wrote a NRPE-plugin used from Nagios/Centreon to gather performance data. So my experience is this:
Issues with LDAP Monitoring
"Uptime" is in whole seconds only (minor issue). SNMP uptime has a finer resolution (but limited range, unfortunately).
Detailed data per peer can only be retrieved through the "Connections", but that's a moment's view only: So if a client opens a connection, does a few operations, then closes the connection, a polling client of the monitor will never see those client operations. Also when needing a cumulative count of operations per peer (or just the number of connections per peer (for a rate)), a monitor client will have to accumulate the numbers from all peer connections. If a connection (with significant operations being done) was closed since the last poll, the total number will look negative. So the monitor client will have to store accumulated numbers for closed connections per peer also (Keeping numbers for all closed connections seems inefficient).
"Current Connections" is returned as monitor _counter_ object (monitorCounter), where in fact it's of type "gauge", opposed to "Total Connections" (which is also returned as monitor counter) which is actually a counter. This makes the code harder than necessary.
What I'm missing are some database (BDB/HDB) runtime statistics.
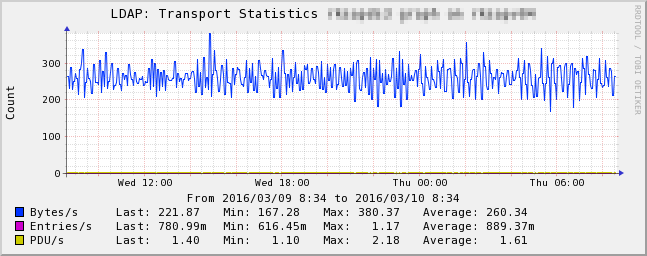
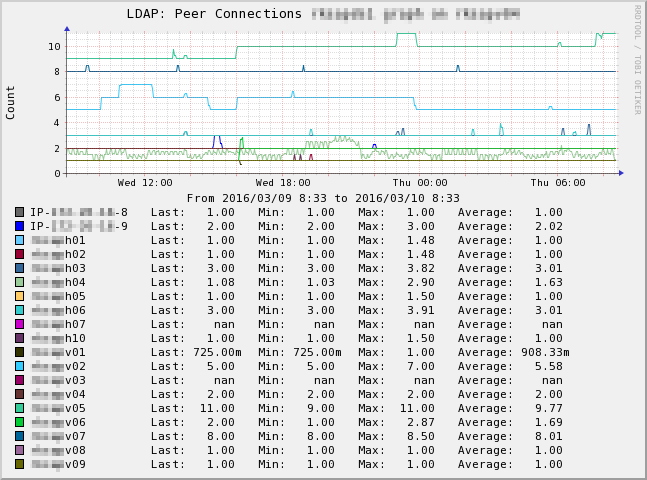
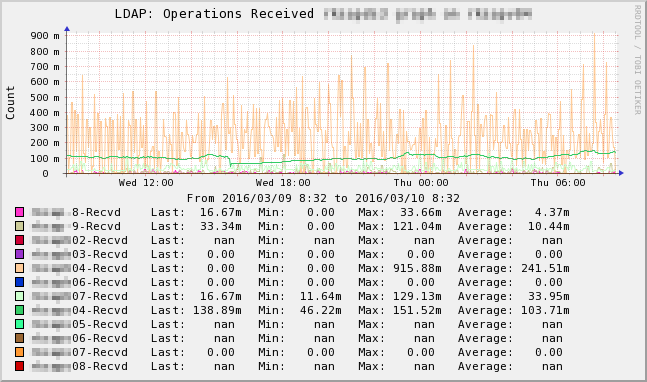
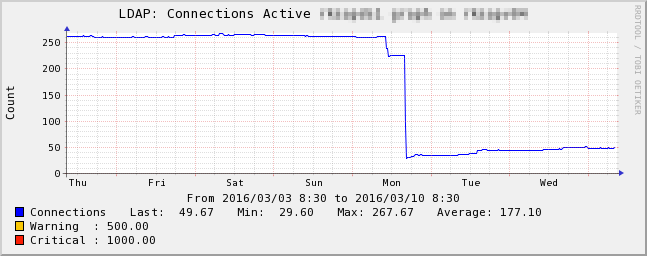
Ok, I'll attach four PNG graphs to let you see how far I got.
Regards, Ulrich
{kind=link}
{kind=link}
{kind=link}
{kind=link}

2016-03-10 8:52 GMT+01:00 Ulrich Windl Ulrich.Windl@rz.uni-regensburg.de:
Hi!
I'd like to inform you about my experience with LDAP monitoring using the cn=monitor DN to query openLDAP. I wrote a NRPE-plugin used from Nagios/Centreon to gather performance data. So my experience is this:
Issues with LDAP Monitoring
"Uptime" is in whole seconds only (minor issue). SNMP uptime has a finer resolution (but limited range, unfortunately).
Detailed data per peer can only be retrieved through the "Connections", but that's a moment's view only: So if a client opens a connection, does a few operations, then closes the connection, a polling client of the monitor will never see those client operations. Also when needing a cumulative count of operations per peer (or just the number of connections per peer (for a rate)), a monitor client will have to accumulate the numbers from all peer connections. If a connection (with significant operations being done) was closed since the last poll, the total number will look negative. So the monitor client will have to store accumulated numbers for closed connections per peer also (Keeping numbers for all closed connections seems inefficient).
"Current Connections" is returned as monitor _counter_ object (monitorCounter), where in fact it's of type "gauge", opposed to "Total Connections" (which is also returned as monitor counter) which is actually a counter. This makes the code harder than necessary.
What I'm missing are some database (BDB/HDB) runtime statistics.
Ok, I'll attach four PNG graphs to let you see how far I got.
Hello,
thanks for sharing this. If you are interested, there are also monitoring plugins available on LTB project: http://ltb-project.org/wiki/documentation#monitoring
Clément.

Ulrich Windl wrote:
Issues with LDAP Monitoring
Aren't you mentioning issues with monitoring in general?
"Uptime" is in whole seconds only (minor issue). SNMP uptime has a finer resolution (but limited range, unfortunately).
Detailed data per peer can only be retrieved through the "Connections", but that's a moment's view only: So if a client opens a connection, does a few operations, then closes the connection, a polling client of the monitor will never see those client operations. Also when needing a cumulative count of operations per peer (or just the number of connections per peer (for a rate)), a monitor client will have to accumulate the numbers from all peer connections. If a connection (with significant operations being done) was closed since the last poll, the total number will look negative. So the monitor client will have to store accumulated numbers for closed connections per peer also (Keeping numbers for all closed connections seems inefficient).
"Current Connections" is returned as monitor _counter_ object (monitorCounter), where in fact it's of type "gauge", opposed to "Total Connections" (which is also returned as monitor counter) which is actually a counter. This makes the code harder than necessary.
Of course Shannon's sampling theorem also applies to IT monitoring.
And of course if your scripts calculate rates, it has to deal with counter reset etc. BTDT.
In general polling based monitoring system like Nagios, check_mk etc. are pretty poor regarding fine-grained performance monitoring. You will always loose information about peak loads happening in those pretty wide time slots of 30+ secs.
If you really need it you can send the logged events to the usual ELK stack (or similar) and analyze whatever you want there [1]. Of course, depending on your OpenLDAP load, you need big and fast log stores.
[1] https://github.com/coudot/openldap-elk
What I'm missing are some database (BDB/HDB) runtime statistics.
Forget about BDB/HDB. MDB is the way to go. ;-)
https://www.openldap.org/its/index.cgi?findid=7770
Ciao, Michael.
Michael Ströder michael@stroeder.com schrieb am 10.03.2016 um 13:50 in
Nachricht 56E16D7A.2070707@stroeder.com:
Ulrich Windl wrote:
Issues with LDAP Monitoring
Aren't you mentioning issues with monitoring in general?
"Uptime" is in whole seconds only (minor issue). SNMP uptime has a finer resolution (but limited range, unfortunately).
Detailed data per peer can only be retrieved through the "Connections",
but
that's a moment's view only: So if a client opens a connection, does a few operations, then closes the connection, a polling client of the monitor
will
never see those client operations. Also when needing a cumulative count
of
operations per peer (or just the number of connections per peer (for a
rate)), a monitor
client will have to accumulate the numbers from all peer connections. If
a
connection (with significant operations being done) was closed since the
last
poll, the total number will look negative. So the monitor client will have
to
store accumulated numbers for closed connections per peer also (Keeping numbers for all closed connections seems inefficient).
"Current Connections" is returned as monitor _counter_ object
(monitorCounter),
where in fact it's of type "gauge", opposed to "Total Connections" (which
is
also
returned as monitor counter) which is actually a counter. This makes the
code harder
than necessary.
Of course Shannon's sampling theorem also applies to IT monitoring.
Sorry, I'm not impressed: It's easy for the server to count the numbers, and I just wonder why it woudln't give it out.
And of course if your scripts calculate rates, it has to deal with counter reset etc. BTDT.
Of course they do. The debug message would read like "UNKNOWN: [3 searches with 12 entries in 0.066s], 95, [Operations.Bind.i: restart detected (95 - 1228173 == -1228078)], 22, [Operations.Unbind.i: restart detected (95 - 1228173 == -1228078)], 9, [Operations.Search.i: restart detected (95 - 1228173 == -1228078)], 92, [Operations.Compare.i: restart detected (95 - 1228173 == -1228078)], 0, [Operations.Modify.i: restart detected (95 - 1228173 == -1228078)], 0, [Operations.Modrdn.i: restart detected (95 - 1228173 == -1228078)], 0, [Operations.Add.i: restart detected (95 - 1228173 == -1228078)], 0, [Operations.Delete.i: restart detected (95 - 1228173 == -1228078)], 0, [Operations.Abandon.i: restart detected (95 - 1228173 == -1228078)], 0, [Operations.Extended.i: restart detected (95 - 1228173 == -1228078)], 19" (".i" is a shortcut for ".initiated")
In general polling based monitoring system like Nagios, check_mk etc. are pretty poor regarding fine-grained performance monitoring. You will always loose information about peak loads happening in those pretty wide time slots of 30+ secs.
But still ist exactly infinite times better than nothing ;-)
If you really need it you can send the logged events to the usual ELK stack
(or similar) and analyze whatever you want there [1]. Of course, depending on your OpenLDAP load, you need big and fast log stores.
[1] https://github.com/coudot/openldap-elk
What I'm missing are some database (BDB/HDB) runtime statistics.
Forget about BDB/HDB. MDB is the way to go. ;-)
There aren't statistics either, and I should be allowed to have an opinion.
https://www.openldap.org/its/index.cgi?findid=7770
Ciao, Michael.

Ulrich Windl wrote:
Michael Ströder michael@stroeder.com schrieb am 10.03.2016 um 13:50 in
What I'm missing are some database (BDB/HDB) runtime statistics.
Forget about BDB/HDB. MDB is the way to go. ;-)
There aren't statistics either, and I should be allowed to have an opinion.
You are allowed to have an opinion, but nobody is required to heed it. BDB/HDB are deprecated, no further development work will be done on them.
https://www.openldap.org/its/index.cgi?findid=7770
Ciao, Michael.
openldap-technical@openldap.org
-
 Clément OUDOT
Clément OUDOT -
 Howard Chu
Howard Chu -
 Michael Ströder
Michael Ströder -
 Ulrich Windl
Ulrich Windl