Re: Antw: syncrepl error (53) with 3-way delta-mmr (consumer state is newer than provider)

On 09/04/2017 08:51 AM, Ulrich Windl wrote:
Sven Mäder maeder@phys.ethz.ch schrieb am 01.09.2017 um 16:53 in
Nachricht 2832441b-362f-9429-8c56-32995cff5ef1@phys.ethz.ch:
Hi Ulrich
Thank you for your response.
On 08/31/2017 09:37 AM, Ulrich Windl wrote:
Hi!
Some of the time ntpd needs to sync may be host name resolution (if you
use
names). Methods to speed up initial synchronization inlude "iburst",
"minpoll"
and adding a large crowd of servers. Note that reducing minpoll could
reduce
the final accuracy (just as increasing "maxpoll" does). Depending on your network and load I would not rely on a time offset less than a few ten milliseconds. How well LDAP can operate then is a different question.
We have 2 timeservers (stratum 1) in our local net with gps clock source: server time1.phys.ethz.ch minpoll 4 maxpoll 10 iburst server time2.phys.ethz.ch minpoll 4 maxpoll 10 iburst
minpoll is already set at its lowest value, although I do not understand what this option does. I may increase its value, increasing accuracy sounds good.
The manual explains what "minpoll" does. Basically it is the starting poll interval. Short values cause adjustment to be made faster than nomal. However if subsequent polls fail, the clock could continue to run with wrong correction values and the accumulate some time error (i.e. make things worse). A big maxpoll might not correct he clock in time. And you probably should have an odd number of time servers.
Reading the correct manuals helps, looks like the debian manpages are outdated (ntp version 1:4.2.8p10+dfsg-3) compared to the manpages of the upstream source tarball (ntp-4.2.8p10.tar.gz) and to the manuals on http://doc.ntp.org/current-stable/. Even the upstream source tarball is not in line with the manuals on the website.According the manual on http://doc.ntp.org/current-stable/confopt.html it is now possible to use a minimal poll interval of 3.
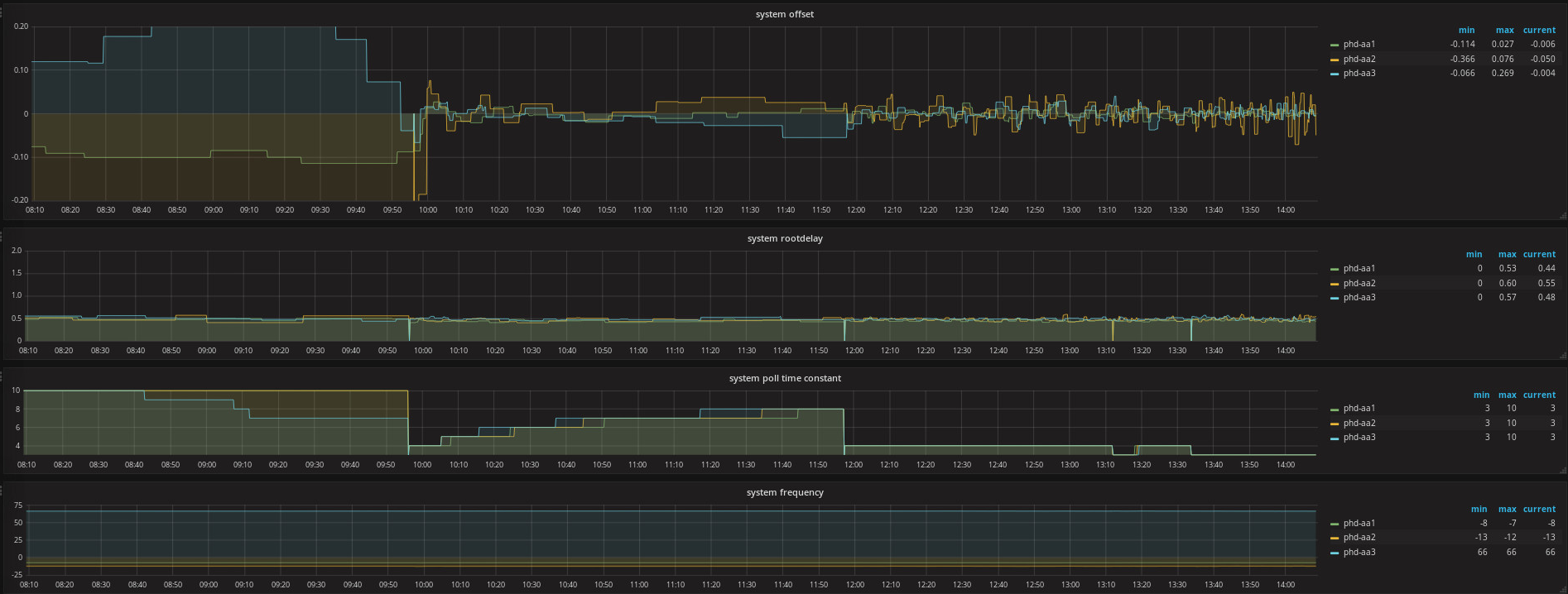
Thanks to your inputs I started playing around with minpoll and maxpoll. Looks like on my setup a maxpoll of 10 is too high, as the accumulated time errorstarts to increase notably from poll interval >6. See attached graph (ntp_graph_phd-aa_20170908.png) or https://people.phys.ethz.ch/~rda/img/ntp_graph_phd-aa_20170908.png
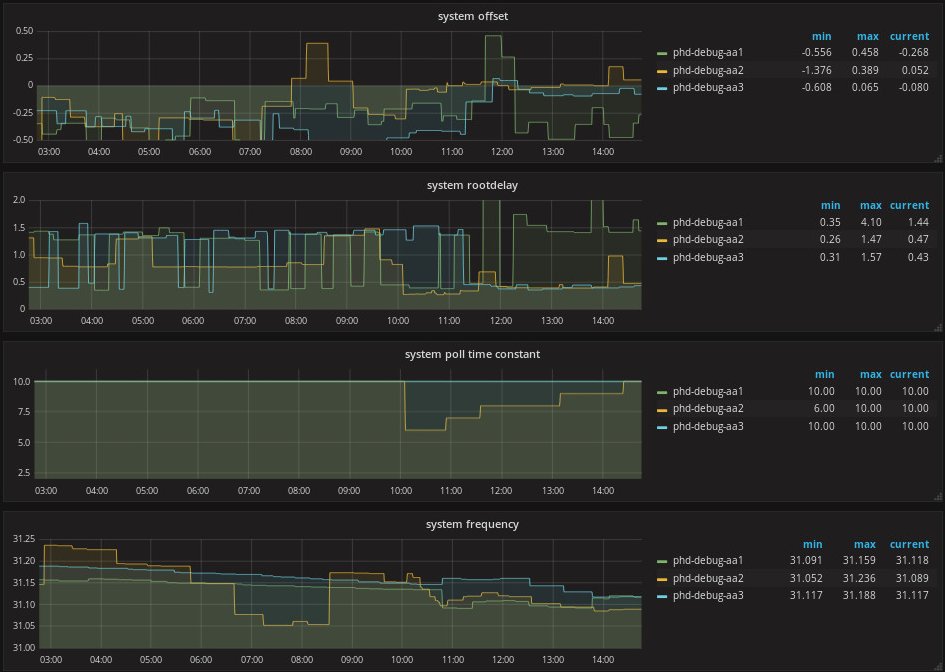
I also noticed, that a higher rootdelay or the variation of the delay has a big impact on the time offset. Under normal conditions we have a delay of 0.3 - 0.4 ms in our local network (offset: ~0.050 ms). But the servers which are in the same subnet as our ntp servers sometimes have to make ARP requests if the poll interval is higher. The ntp server has to do the same. This results in a root delay of ~1.5ms, which I think confuses ntp which in turn results in offsets of 0.500-1.500 ms. See attached graph (ntp_graph_phd-debug-aa_20170908.png) or https://people.phys.ethz.ch/~rda/img/ntp_graph_phd-debug-aa_20170908.png
# ntptrace localhost: stratum 2, offset 0.000008, synch distance 0.031825 time1.ethz.ch: stratum 1, offset -0.000001, synch distance 0.000298, refid 'PPS'
# ntpq -c pe remote refid st t when poll reach delay offset jitter
============================================================================
== LOCAL(0) .LOCL. 5 l 149m 64 0 0.000 0.000 0.000 *time1.ethz.ch .PPS. 1 u 251 256 377 0.426 0.009 0.026 +time2.ethz.ch .PPS. 1 u 64 256 377 0.430 -0.003 0.019
Looks like the time offset is only a few microseconds once ntp is in sync.
Yes, looks good.
Also note for Linux (on most platforms) and NTP one problem is that the frequency correction needed for the clock can vary significantly between
boots;
thus the tijme for "perfect sync" can be quite long. See attached image for
an
example.
This is very interesting, we will look further into this. I am thinking about waiting in the startup process until ntp is in "perfect sync"and start slapd after that. Maybe I can use the loopstats file to check/automate this.
Perfect sync can take quite some time (due to design of NTP) [From RFC 1305: "This yields a PLL risetime of about 52 minutes, a maximum overshoot of about 4.8 percent in about 1.7 hours and a settling time to within one percent of the initial offset in about 8.7 hours."] The good thing is that NTP itself provides performance numbers to check. Maybe start with clk_wander being low, rootdisp being low, and offset being low. There are some pathological cases where the numbers are low while the clock in in a bad condition.
Thanks, monitoring these numbers using graphs helps me a lot.I am looking forward to the results of some long term tests with different settings, to see what gives the most stable and accurate time for our ldap servers.
Updating one entry on different servers within a very short time (shorter
than
the time of syncing) will probably cause trouble. What real-life situation causes such?
Probably none. But we have a logparser, which writes "last use" statistics of our users to ldap, this is done in "realtime". We also use openldap as kerberos KDC database backend, which writes on successful/failed authentication attempts. The chance is probably very low if the time offset is lower than the network delay.
Maybe you could centralize the logparser to run on only one host at a time...
Regards, Ulrich
Kind regards Sven
{kind=link}
{kind=link}
openldap-technical@openldap.org
-
 Sven Mäder
Sven Mäder