
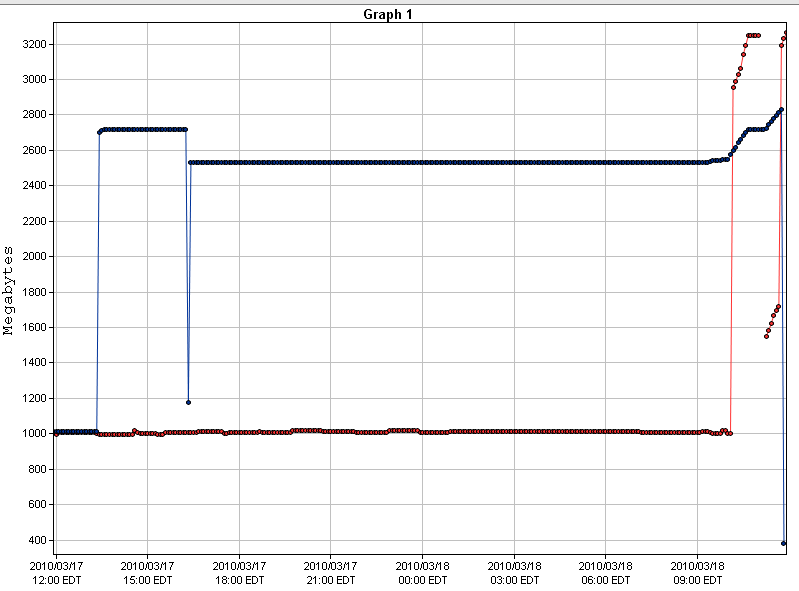
I have been running into some huge memory spikes, and was wondering if its normal, or if anyone has seen it before.
Archtecture: OpenLDAP 2.4.21 Running on RH4 Ulimit open files upped to 4096
Masters: auth01.cmc, auth01.inflow Running n-way multimaster
Slaves: rsa01.inflow, rsa02.inflow, rsa03.cmc, rsa04.cmc Syncrepl running off both masters refreshAndPersist with retry=²60 +²
Here is a graph of the spikes we are seeing on auth01.cmc and auth01.inflow
It also looks like the slave servers are only connecting to auth01; when looking at netstat on the auth boxes, I see:
From auth01.phil:
tcp 0 0 auth01. inflow:ldap rsa04.cmc:46851 ESTABLISHED tcp 0 0 auth01.inflow:ldap rsa01.inflow:61648 ESTABLISHED tcp 0 0 auth01.inflow:ldap rsa01.inflow:61686 ESTABLISHED tcp 0 0 auth01.inflow:ldap rsa01.inflow:61683 ESTABLISHED tcp 0 0 auth01.inflow:48882 rsa02.inflow.:ldap ESTABLISHED tcp 0 109500 auth01.inflow:ldap rsa03.cmc:45798 ESTABLISHED tcp 0 0 auth01.inflow:ldap rsa02.inflow.:8773 ESTABLISHED
From auth01.cmc:
tcp 0 0 auth01.cmc:ldap rsa02.inflow:8885 ESTABLISHED tcp 1 0 auth01.cmc:24310 rsa03.cmc:ldap CLOSE_WAIT tcp 0 0 auth01.cmc:ldap rsa01.inflow:61657 ESTABLISHED
With refreshAndPersist, shouldn¹t each slave be connected to each host configured in syncRepl, and keep that connection?
This is a pretty big issue today we had a master crash; got:
Mar 18 14:39:43 auth01 slapd[17498]: bdb(dc=comcast,dc=com): malloc: 16422: Cannot allocate memory Mar 18 14:39:43 auth01 slapd[17498]: bdb(dc=comcast,dc=com): malloc: 32000: Cannot allocate memory Mar 18 14:39:43 auth01 slapd[17498]: bdb(dc=comcast,dc=com): PANIC: Cannot allocate memory Mar 18 14:39:43 auth01 slapd[17498]: bdb(dc=comcast,dc=com): PANIC: fatal region error detected; run recovery Mar 18 14:39:43 auth01 slapd[17498]: slap_graduate_commit_csn: removing 0x9b5d3ec8 20100318143943.437380Z#000000#001#000000 Mar 18 14:39:43 auth01 slapd[17498]: bdb(dc=comcast,dc=com): uniqueMember.bdb: write failed for page 35805 Mar 18 14:39:43 auth01 slapd[17498]: bdb(dc=comcast,dc=com): uniqueMember.bdb: unable to flush page: 35805
These boxes have 8gig ram; I am trying to figure out if this is normal and I just need to up the ram.
Thanks for any help in advance.
{kind=link}

--On Thursday, March 18, 2010 10:46 AM -0600 Mathew Rowley mathew_rowley@cable.comcast.com wrote:
I have been running into some huge memory spikes, and was wondering if its normal, or if anyone has seen it before.
How many entries are in your database? What is the size of your database on disk? What are your cachesize settings for BDB? What are your cachesize settings for OpenLDAP (cachesize, idlcachesize, dncachesize)?
--Quanah
--
Quanah Gibson-Mount Principal Software Engineer Zimbra, Inc -------------------- Zimbra :: the leader in open source messaging and collaboration
openldap-software@openldap.org
-
 Mathew Rowley
Mathew Rowley -
 Quanah Gibson-Mount
Quanah Gibson-Mount